
MuseTalk一种实时高质量口型同步模型(在 NVIDIA Tesla V100 上为 30fps+)。
意思是:性能高于此显卡就可以开直播,实现实时直播流。
MuseTalk 可以与输入视频一起应用,例如由MuseV生成的视频,作为完整的虚拟人解决方案。
意思是:先利用MuseV生成视频,再由MuseTalk对视频口型。

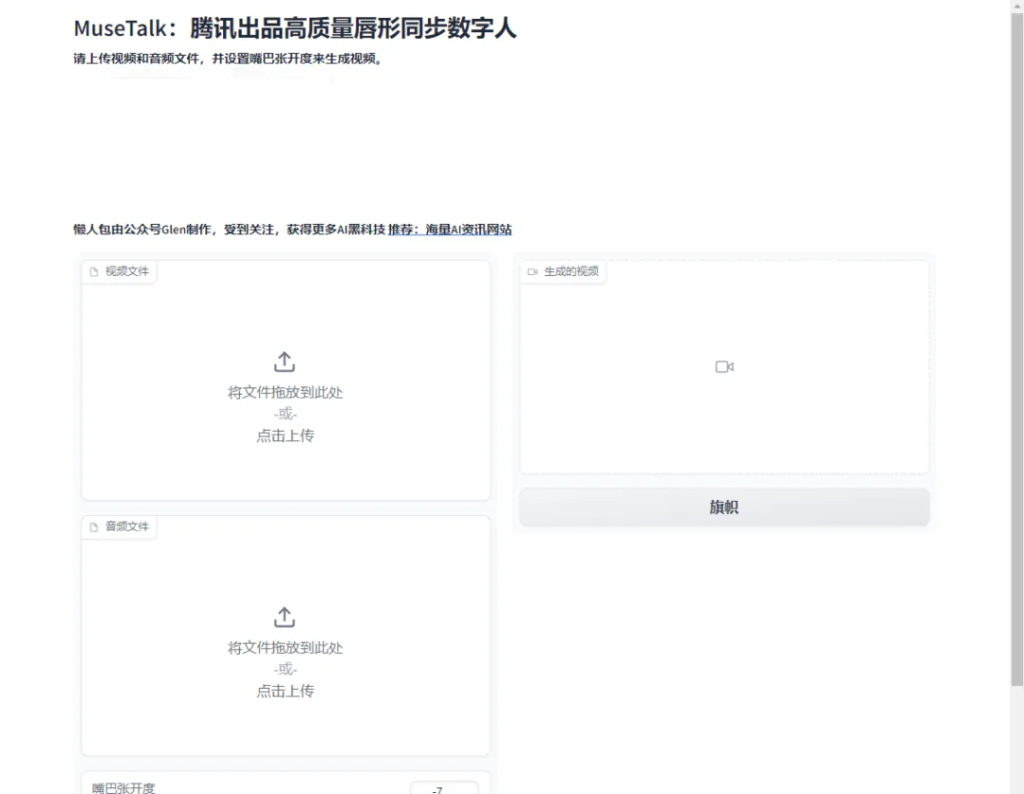
五、使用方法
功能特性
-
MuseTalk是一个实时高质量音频驱动的口型同步模型,在 的潜在空间中进行训练ft-mse-vae,其中
- 根据输入音频修改未见过的脸部,脸部区域的大小为
256 x 256。 - 支持中文、英文、日文等多种语言的音频。
- 支持 NVIDIA Tesla V100 上 30fps+ 的实时推理(直播流,可以开直播的意思)。
- 支持修改面部区域中心点建议,这显著影响生成结果。
- 检查点可用在 HDTF 数据集上进行训练。
- 对于视频配音,我们应用了自主开发的工具,可以识别说话的人。
MuseTalk 在潜在空间中进行训练,其中图像由冻结的 VAE 进行编码。音频由冻结whisper-tiny模型编码。生成网络的架构借鉴了UNet stable-diffusion-v1-4,其中音频嵌入通过交叉注意力融合到图像嵌入。
bbox_shift 调整张嘴大小
🔎我们发现面罩上界对张口度有重要影响。因此,为了控制掩模区域,我们建议使用该bbox_shift参数。正值(朝下半部分移动)会增加嘴巴张开度,而负值(朝上半部分移动)会减少嘴巴张开度。
您可以先使用默认配置运行以获得可调整的值范围,然后在此范围内重新运行脚本。使用默认例子,运行默认配置后,显示可调整值范围为[-9, 9]。然后,为了减少嘴巴张开度,我们将值设置为-7。
总结
MuseTalk是一个实时高质量音频驱动的口型同步模型,专为实现虚拟数字人口型与音频的精准同步而设计。
如果您想进行在线视频聊天,建议您使用MuseV生成视频,并提前进行必要的预处理,例如人脸检测、人脸解析等。在线聊天时,只涉及UNet和VAE解码器,这使得MuseTalk具有实时性。
开源地址:
MuseV简介:腾讯版Sora、Ai数字人、基于世界的Ai视频模型(附整合包)
服务声明: 本网站所有发布的软件和学习资料以及牵涉到的源码均为网友推荐收集各大资源网站整理而来,仅供功能验证和学习研究使用,您必须在下载后24小时内删除。不得使用于非法商业用途,不得违反国家法律,否则后果自负!一切关于该资源商业行为与本站无关。如果您喜欢该程序,请支持购买正版源码,得到更好的正版服务。如有侵犯你的版权合法权益,请邮件与我们联系处理删除83855733@qq.com,本站将立即更正。请作者喝杯咖啡
评论(9)
这个文件估计很大吧
评论就可以下载了么
感谢大佬
感谢打捞呀
i see see
想要下载
111
我要成为榜一大哥
谢谢分享