
一、AudioCraft是什么?
AudioCraft是Meta AI免费开源的一款深度学习进行音频处理和生成的库。可满足您所有的生成音频需求:音乐、音效以及原始音频信号训练后的压缩。 它具有最先进的EnCodec音频压缩器/标记器,沿着MusicGen,一个简单可控的音乐生成LM,具有文本和旋律调节。 素材训练使用2万小时的授权音乐来训练MusicGen。

二、AudioCraft的项目地址:
1、Github地址:
https://audiocraft.metademolab.com/
2、项目地址:
https://audiocraft.metademolab.com/
3、论文地址:
https://arxiv.org/abs/2306.05284
4、样本演示:
https://ai.honu.io/papers/musicgen/
5、在线试用:
https://huggingface.co/spaces/facebook/MusicGen
6、模型下载:
https://huggingface.co/facebook/musicgen-small
三、AudioCraft的技术剖析:
MusicGen 和 AudioGen 都包含一个自回归语言模型 (LM),该模型在压缩的离散音乐表示流(即标记)上运行。我们引入了一种简单的方法来利用令牌并行流的内部结构,并表明,通过单一模型和优雅的令牌交错模式,我们的方法可以有效地对音频序列进行建模,同时捕获音频中的长期依赖性,并允许我们生成高质量的音频。
我们的模型利用 EnCodec 神经音频编解码器从原始波形中学习离散音频标记。EnCodec 将音频信号映射到一个或多个离散令牌的并行流。然后,我们使用单个自回归语言模型对来自 EnCodec 的音频标记进行递归建模。然后生成的令牌被馈送到 EnCodec 解码器,将它们映射回音频空间并获得输出波形。最后,可以使用不同类型的条件模型来控制生成,例如使用预训练的文本编码器进行文本到音频应用。
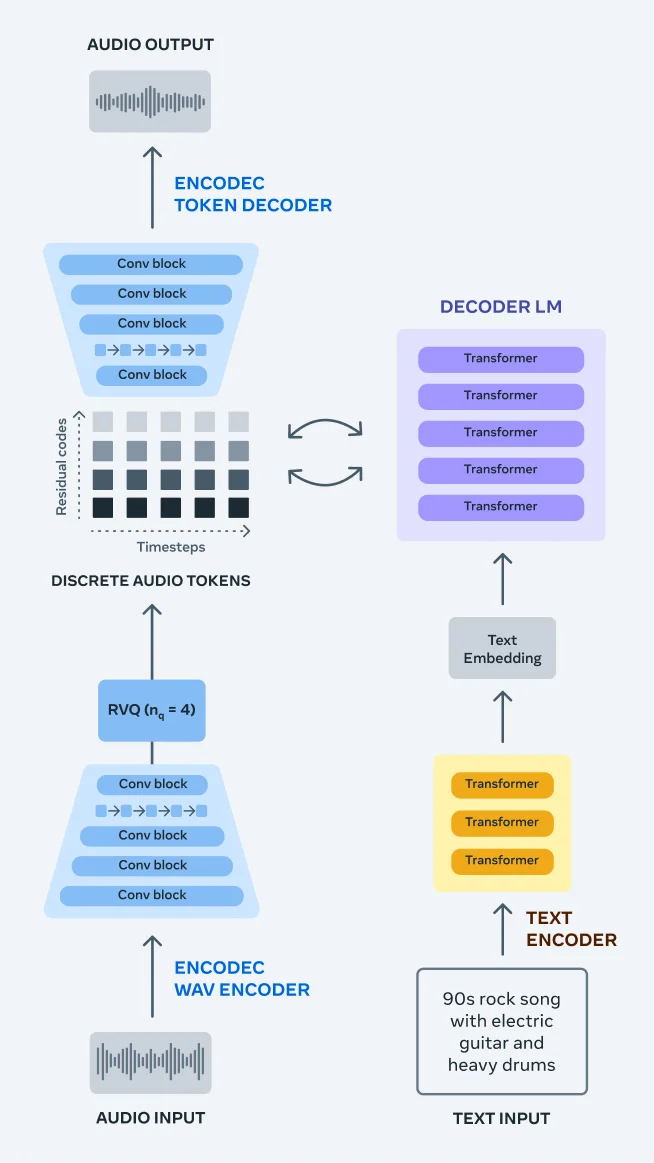
四、AudioCraft的模型概述:
目前,AudioCraft 包含以下训练代码和推理代码:
- MusicGen: 最先进的可控文本到音乐模型。
- AudioGen: 最先进的文本到声音模型。
- EnCodec: 最先进的高保真神经音频编解码器。
- Multi Band Diffusion: 使用扩散的 EnCodec 兼容解码器。
- MAGNeT: 最先进的文本到音乐和文本到声音的非自回归模型。
AudioGen 专注于文本到声音的生成,并学会了从环境声音中生成音频。
MusicGen 根据用户提供的文本输入生成多样化且长的音乐样本。
五、怎么使用AudioCraft?
为了让更多用户能够轻松体验这一技术,我们将AudioCraft打包成了一键启动包。现在,您无需繁琐地配置Python环境,只需简单点击即可启动程序,从而避免了潜在的环境配置问题。
- 下载压缩包,解压到电脑D盘,最好不要有中文路径;
- 解压后点击启动.bat文件即可运行(文件可能会被误杀,请添加为信任);
- 浏览器访问:http://127.0.0.1:7860/,即可正常使用。
评论(0)